

At the time of writing Tensorflow version was 2.4.1
In TF, we can use tf.keras.layers.LSTM and create an LSTM layer. When initializing an LSTM layer, the only required parameter is units. The parameter units corresponds to the number of output features of that layer. That is units = nₕ in our terminology. nₓ will be inferred from the output of the previous layer. Hence the library can initialize all the weight and bias terms in the LSTM layer.
TF LSTM layer expects a 3 dimensional tensor as input during forward propagation. This input should be of the shape (batch, timesteps, input_features). This is shown in the code snippet below. Suppose we are using this LSTM layer to train a language model. Our input will be sentences. The first dimension corresponds to how many sentences we use as one batch to train the model. The second dimension corresponds to how many words are present in one such sentence. In practical setting, the number of words in each sentence varies from sentence to sentence. So, in order to batch these sentences, we can select the length of the longest sentence in the training corpus as this dimension and pad the other sentences with trailing zeros. The last dimension corresponds to the number of features used to represent each word. For simplicity, if we say, we are using one-hot encoding and there are 10000 words in our vocabulary, then this dimension will be 10000.
But when initializing the layer, if we set time_major = True, then the input will be expected in the shape – (timesteps, batch, feature).
As seen from the above code snippet, the output of the LSTM (with default parameters) is of shape (32,4), which corresponds to (batch, output_features). So if we go back to the example of the language model, the output has one vector per sentence, with nₕ number of features per sentence (nₕ = units = no. of output features). This one vector (per sentence) is the output of the LSTM layer corresponding to the last timestep T (last word of the sentence). This output is hᵀ in our notation. This is depicted in fig. 3.

However, if we want to stack multiple LSTM layers, the next layer also expects a time series as input. In such situations, we can set return_sequences=True when initiating the layer. Then the output will be of shape (32,10,4), which corresponds to (batch, timesteps, output_features). If return_sequence is set to True, then hᵗ : ∀t = 1,2…T will be returned as output. This is shown in the code snippet below and the first LSTM layer in fig. 4.
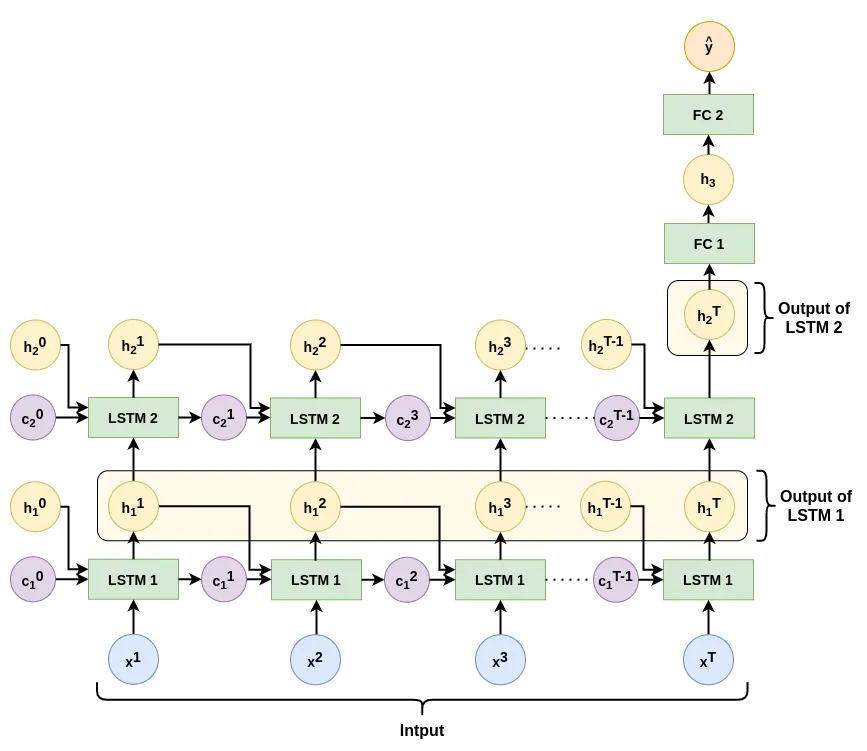
LSTM 1 layer outputs a sequence and the LSTM 2 outputs a single vector. (diagram by the author)If we want to get the cell state (cᵗ) as an output, we need to set return_state=True when initiating the layer. Then We get a list of 3 tensors as output. According to documentation, if we set both return_sequences=True and return_state=True, these three tensors will be — whole_seq_output, final_memory_state,and final_carry_state. This is shown in the code snippet below.
In our notation,
whole_seq_output— output corresponding to all timesteps.hᵗ : ∀t = 1,2…T; Shape —(batch, timesteps, output_features)final_memory_state— Output corresponding to the last timestep.hᵀ; Shape —(batch, output_features)final_carry_state— Last cell state.cᵀ; Shape —(batch, output_features)
If we set return_sequences=False and return_state=True, then these three tensors will be — final_memory_state, final_memory_state, and final_carry_state.
A single LSTM layer has five places where activation functions are used. But if we look at the parameters, we see only two parameters to set activation functions — activation and recurrent_activation. If we set a value to the activation parameter, it changes the activation applied to the candidate vector and the activation applied to the cell state just before element-wise multiplication with the output gate. Setting a value to recurrent_activation will change the activation functions of forget gate, update gate, and output gate.
Other parameters are quite self-explanatory or seldom used. One other thing to note is, we can set unroll=True, and the network will be unrolled. It will speed up the training process but will be memory intensive (since the same layer is copied multiple times).
The following code snippet implements the model shown in fig. 4 using TF. Note the output shape of each layer and the number of trainable parameters in each layer.
Be the first to comment