

Introduction
Taboola is the leading recommendation engine in the $80+ billion open web market. The company’s platform, powered by deep learning and artificial intelligence, reaches almost 600 million daily active users. The company’s ML inference infrastructure consisted of 7 large-scale Kubernetes clusters across ten on-premise data centers and tens of thousands of cores.
Over recent months, we’ve witnessed an increase in the Kubernetes worker nodes load averages that initially seemed aligned with rising traffic levels. However, further investigation revealed significant discrepancies in servers load-to-request rate ratio across data centers. Closer examination pointed to a notable correlation with the proportion of Skylake CPUs in each cluster, particularly in Chicago and Amsterdam, where Skylake usage was significantly higher (46% and 75%, respectively) compared to other locations (20-30%).
The Skylake CPU Frequency Challenge
It’s been observed and documented across the web that Skylake CPUs experience frequency downclocking when utilizing the AVX512 instruction set, with the impact intensifying as more cores employ it. While we previously adopted custom-compiled binaries with optimized mtune/march flags to disable or enable AVX512 on specific CPU models in TensorFlow 1.x, migrating to TensorFlow 2.x initially seemed to rectify the issue with performance improvements out-of-the-box.
Unveiling the Root Cause: oneDNN’s JIT and AVX512
Finding the root cause in an environment that includes heterogeneous CPU families, constant models, and traffic level changes can be challenging so our troubleshooting journey began with the basics like verifying the servers’ governor is set to performance, there was no change in servers tuned profile and examining environmental factors like servers room temperature to rule out external influences. Taking a closer look into performance metrics showed that all the servers in the datacenter had load average increase. (We use a “least requests” load balancing algorithm to compensate for the heterogenetic CPU types.)
It was interesting to observe that there was more of an impact on Skylake based servers. This impact included frequency reduction, and degradation in inference requests per CPU core metric.
Next we shifted our focus to investigating AVX512 usage on the Skylake servers. Initial probes using the arch_status under the /proc filesystem suggested minimal AVX512 involvement:
But as the documentation noted, there is an option for false negatives.
Running more comprehensive analysis using perf uncovered a contrasting scenario:
The perf output illuminated substantial level 2 core throttling attributed to AVX512, examining the ratio between level2 to level1 throttling showed 4 of 5 ratio.
In parallel, our Tensorflow workload where in the process of upgrading from version 2.7 to 2.13 analyzing a few Tensorflow 2.7 workloads using perf showed much lower AVX512 usage with a ratio of 1 of 3.
Note that in our environment, the Tensorflow process is not pinned to specific cores, so the results have a lot of “noise” from cross-process CPU time on the same physical core.
However, TensorFlow serving code didn’t explicitly enable AVX512 compilation, with only AVX and SSE4.2 flags present in the .bazelrc file. The key discovery came from TensorFlow 2.9 release notes: oneDNN was now enabled by default. This library dynamically detects supported CPU instruction sets like AVX512 and employs Just-in-Time (JIT) compilation to generate optimized code.
Crafting a Workaround: Limiting oneDNN’s Instruction Set
Following oneDNN documentation, we implemented a workaround to constrain the instruction set based on the CPU family. Added to the image entrypoint bash script a simple test to detect CPU type and set the following environment variable to restrict oneDNN to AVX2:
Outcome: Performance Uplift and Reduced Load
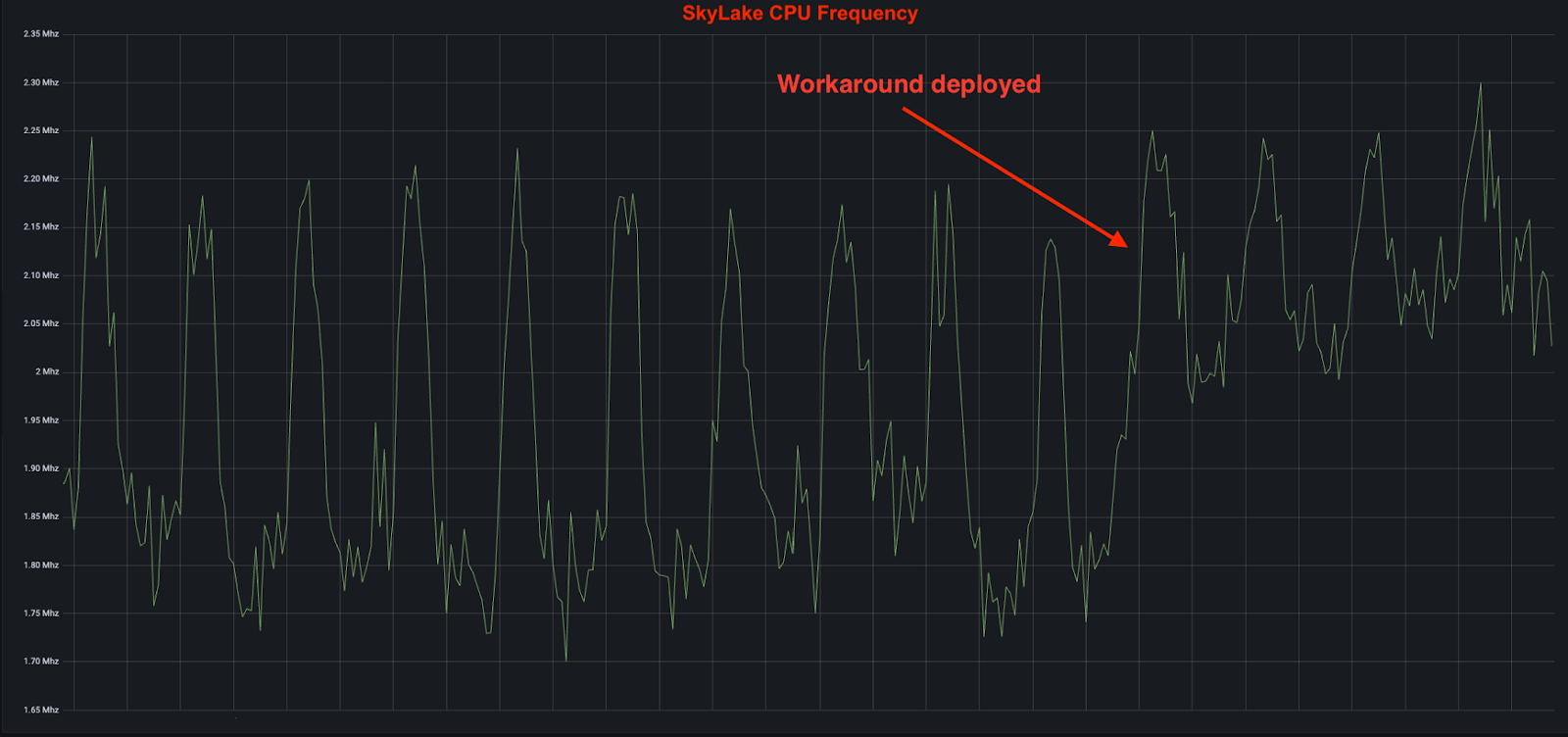
Deploying this fix resulted in a notable improvement:
- ~11% increase in average CPU frequency.
- ~11% decrease in peak 15-minute load average.
- ~10-15% boost in inference requests per used CPU core.
Key takeaways and considerations:
- Prioritize CPU compatibility: When deploying deep learning workloads across diverse CPU architectures, carefully evaluate their instruction set support and potential performance implications.
- Stay informed about framework updates: Regularly review release notes and changelogs of frameworks like TensorFlow to understand introduced features and their potential impact, especially on specific hardware configurations.
- Leverage performance analysis tools: Employ tools like perf to gain fine-grained insights into CPU behavior and pinpoint performance bottlenecks.
Let’s Be Greedy: Compiling Tensorflow with -march Tuning
TODO – Add the tensorflow compile with icelake flag testing….
After the successful instruction set tuning for Skylake, we wanted to check if we can squeeze a few more drops of performance.
We compiled a few Tensorflow serving binaries with different march options by adding the following to .bazelrc and pass the relevant build parameter at build time:
After pushing the images to our local repository we created a custom image and COPY the different binaries.
We set the ENTRYPOINT to launch a bash script that will execute the binary based on the CPU Family.
After deploying the new image to production and monitoring its performance we didn’t observe any performance boost, seems the heavy lifting is done by the OneDNN library
Moving Forward: Continuous Monitoring and Tuning
Our experience highlights the importance of proactive performance monitoring and optimization, especially in heterogeneous infrastructure. We’ll continue to closely monitor cluster performance, explore deeper optimizations where applicable, and stay up-to-date with advancements in TensorFlow and related libraries. We are already excited to test the impact of AMX mixed precision on our servers running Intel Sapphire Rapids CPU family.
Be the first to comment