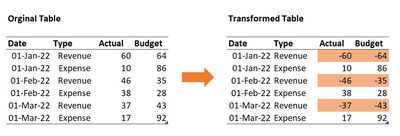
https://blog.tensorflow.org/2023/11/half-precision-inference-doubles-on-device-inference-performance.html https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjLe00EnYz8eKv0IaUn3KfPZnEa4ubDV7Ay2qqIFnOYEMLOh6ybHdH9RhUUrwhYgaccnNkTLe8pID8hvyyKd88JqJL2jK6-ePMxmsddBPcGPktJ_i_EUKmJI1x_YMv6gK3DHZzMqtWIw7Zc5Rx5eHDJH0zNSc-Cnp92ue4WYVWX9P5ATGCnOVeFx-jsI2c/s1600/TensorFlow_HalfPrecisionInference_1024x512.png November 29, 2023 — Posted by Marat Dukhan and Frank Barchard, Software EngineersCPUs deliver the widest reach for ML inference and remain the default target for TensorFlow Lite. Consequently, improving CPU inference performance […]