

In this blog, we will show you how to do text analysis using Python to identify parts of speech in text data within Power BI. We will cover the steps for using Python for text analysis and provide examples and tips to help you get started with your own text analysis projects. You can watch the full video of this tutorial at the bottom of this blog.
Source Data
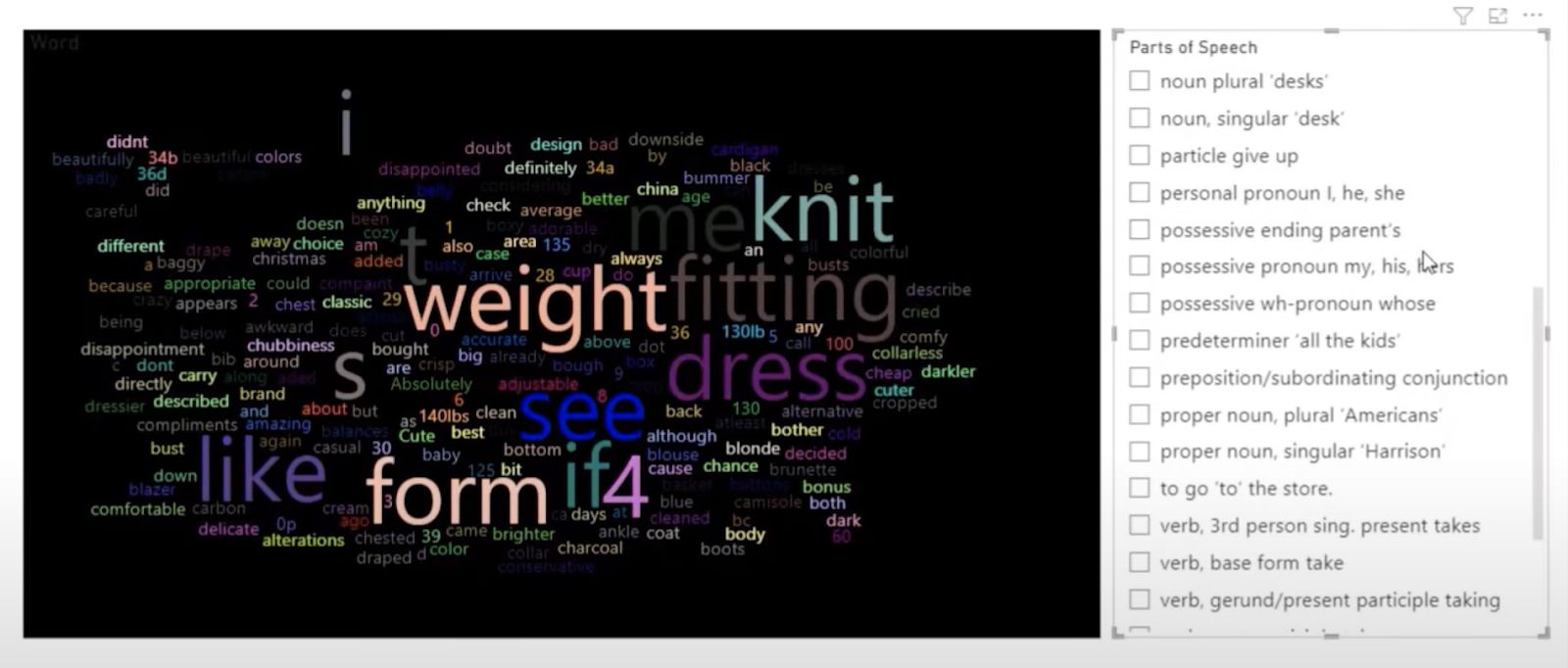
In this tutorial, we will use an out-of-the-box word cloud containing the texts that we’ll be evaluating. This is shown on the left side of the image below. On the right side, we have the filters to identify the different parts of speech, for example, adjectives or verbs.
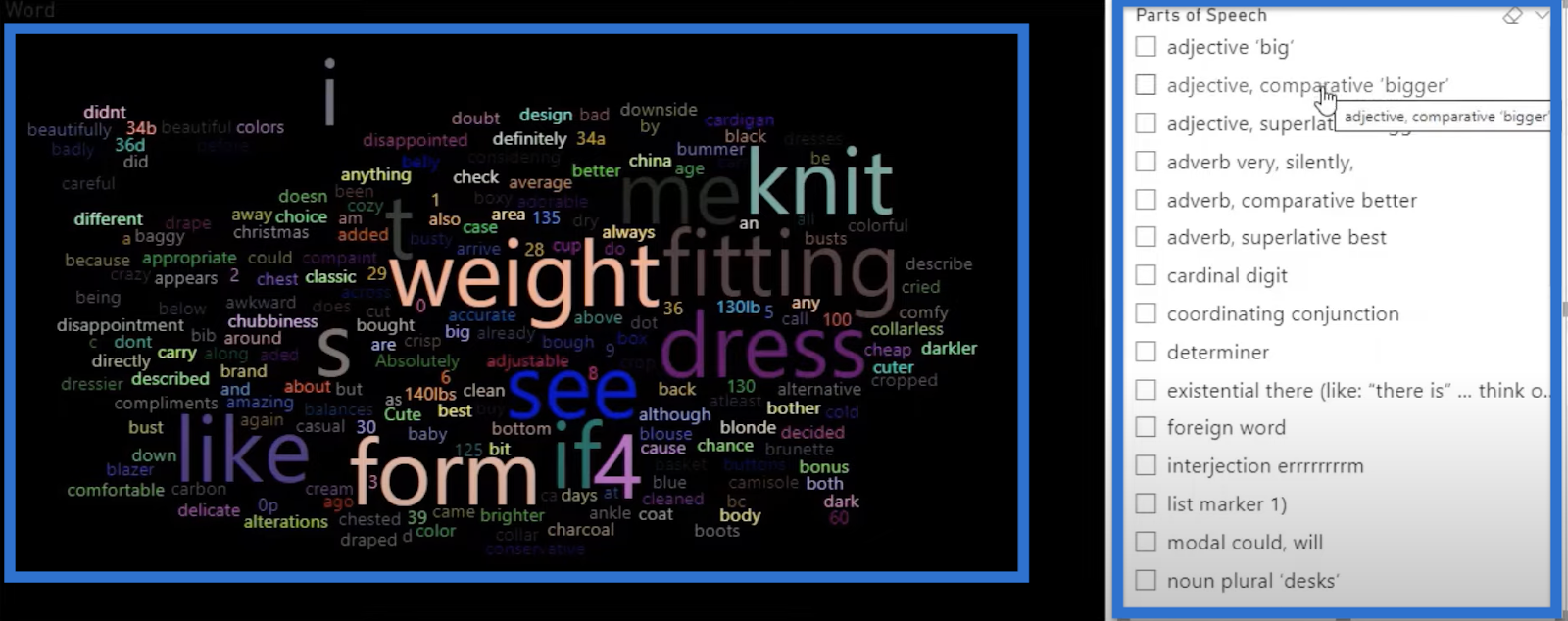
We can filter out words that are adverbs, nouns, different types of nouns or verbs, and verb bases. This is very useful when creating a marketing campaign and looking for words in your customer reviews.
Let’s start by opening our Power Query editor.
In our source data, we have columns for the IDs, age, title, and review text. We will focus on the Review Text column, and we’ll be parsing it out to do our text analysis. There are also other categories that may be useful in our analysis.
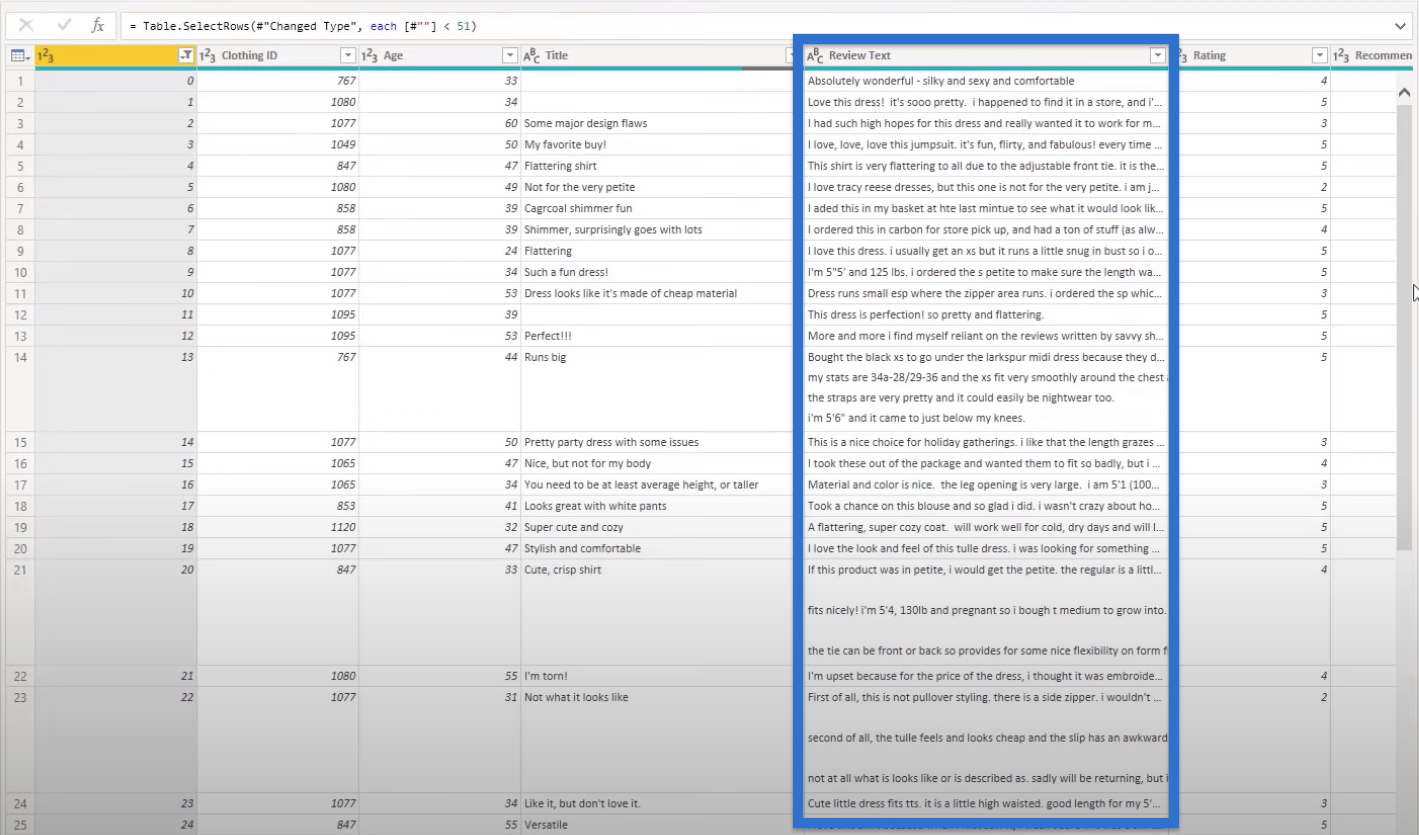
Text Analysis Using Python
Let’s start with the normal data that we brought in. The first thing we’ll do is filter the rows because we have a lot of data, and when we do text analysis, it takes time.
To filter our data, take the first 50 rows to make the text analysis a little bit faster.

Once filtered out, go to Transform and Run Python script. We will code everything in here because there’s not a lot of code.

Importing The Packages
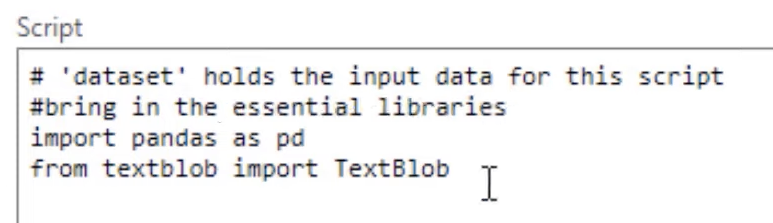
Let’s bring in two packages for our Python text analysis using our Python script editor. We will “import pandas as pd”, our data manipulation library to be saved as variable pd. And then “from text blob”, we will “import TextBlob” with a capital in between the words.
We can always document what we’re doing by putting a document string. Let’s write #bring in the essential libraries on top of our packages.
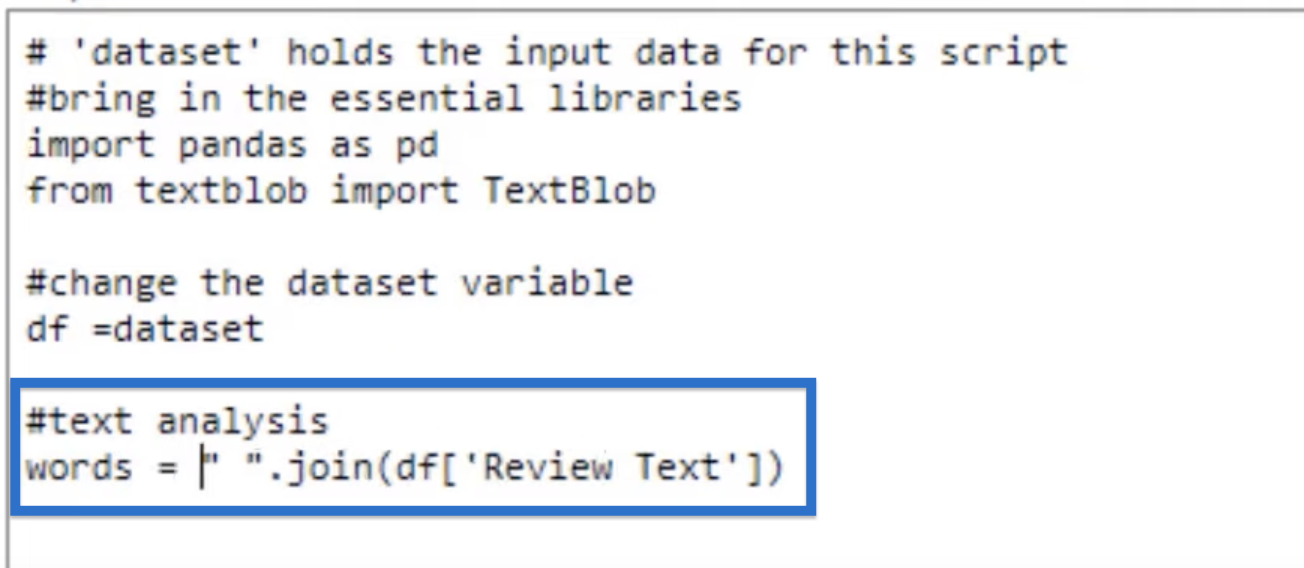
Renaming The Variable
In the first line of our script, there is this line provided by Power BI that says # ‘dataset’ holds the input data for this script. This line says that our data is called a dataset.
So let’s change that because it takes too long to write “dataset”. Type in #change the dataset variable and df = dataset in the next line.

Now it’s shorter to write our variable.
Doing The Text Analysis
Let’s proceed with our text analysis. Recall that our review texts are in a column with individual cells. This setup is not really helpful to us because we want all the texts together so we can perform an analysis on it.
However, we don’t want them to be joined without a space, so let’s start our code with a space inside a double quotation mark.
Then let’s add .join and isolate our review text column by using our df variable, which holds the dataset. Type ‘Review Text’ placed inside a bracket notation which isolates the column.
This code will join everything, but we need to save it so let’s create a variable called words.
Once we have all of the words together, we can then use our text blob to start analyzing the words.
The first thing to do is create our parts of speech using the blob variable which we need to pass out words to a text blob. We’re going to use that text blob and pass in the text, which is our words. This is typed as blob = TextBlob(words).
Now that we have that blob, we will then take it and create our parts_of_speech variable using blob.tags. The tags will be the abbreviations for each one of the parts of speech.
What we’re going to do next is save this as a data frame using Pandas that we brought in. Let’s call it our data which is equal to the pd.DataFrame and we’re bringing in our parts_of_speech.

Let’s click OK to run our code. After running our code, we should get a table of our variables. We have the dataset or our original data. We also have our data and the df.
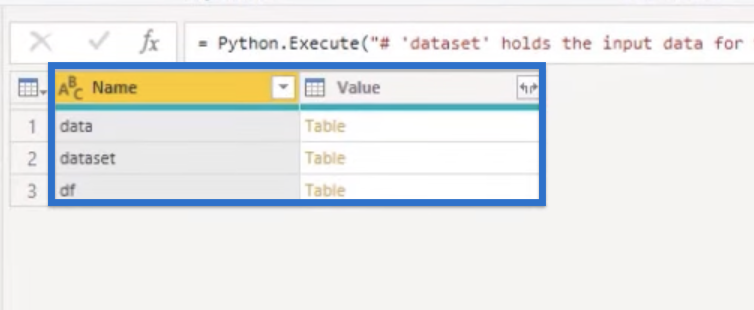
If you didn’t get the intended results, we’ll show you the different ways to avoid some errors that you may get in the code.
Fixing The Code For Text Analysis In Python
Sometimes, we may need to be very explicit in changing the format of the text that we’re concerned with.
We can do that by calling our df variable, isolating ‘Review Text’ placed inside a bracket notation, and then changing the type to strings using .astype(‘str’). Then just re-save this into the df variable.
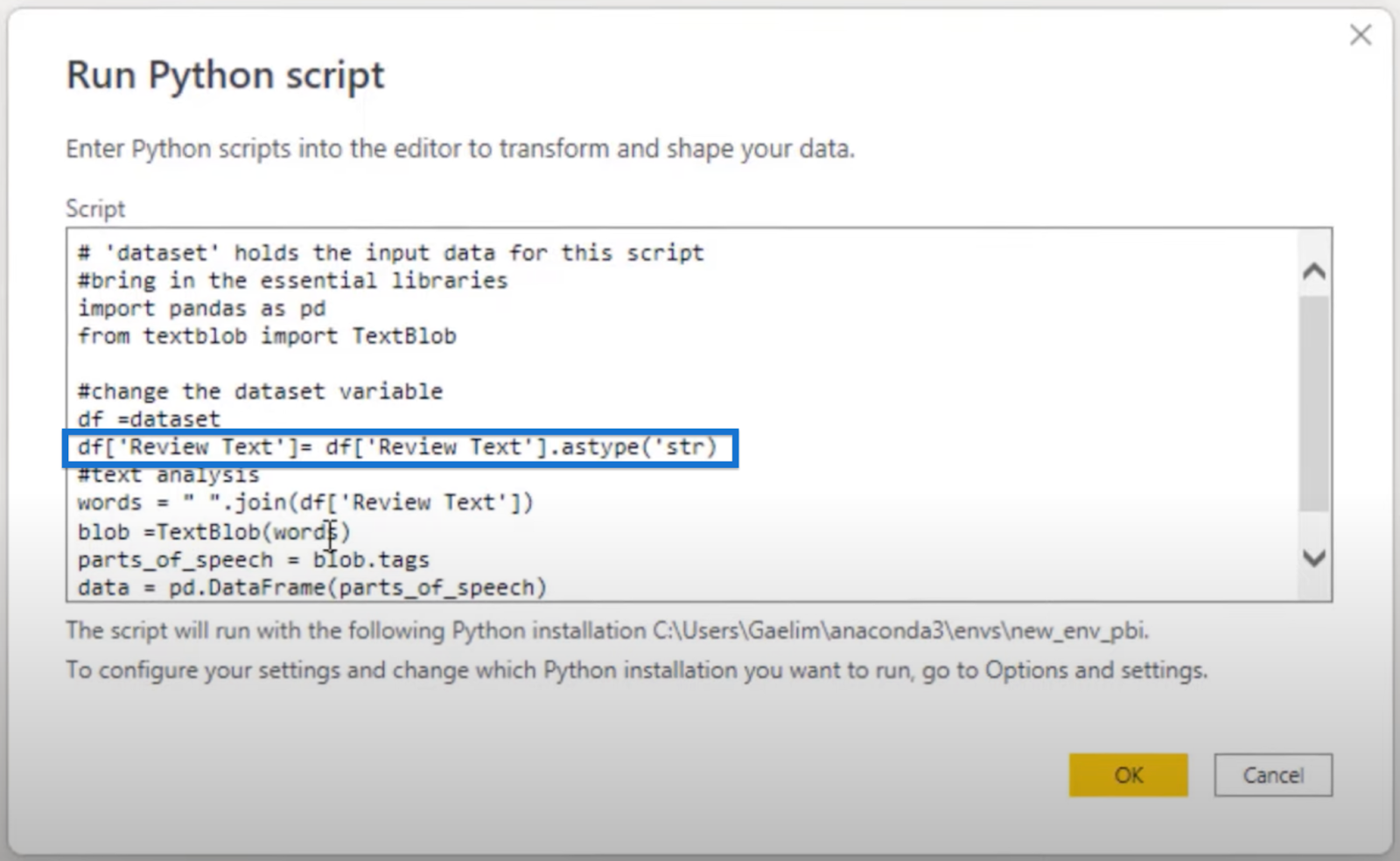
Click OK to rerun the code. We should get the same results as we got earlier.
Now, we want to open our data, the last variable that we brought in to see what that looks like.
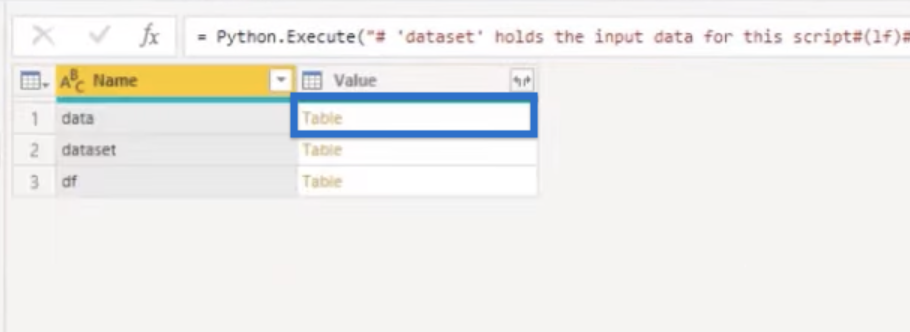
We should have all our words broken up by parts of speech. We didn’t name our columns yet, but we can easily do that.
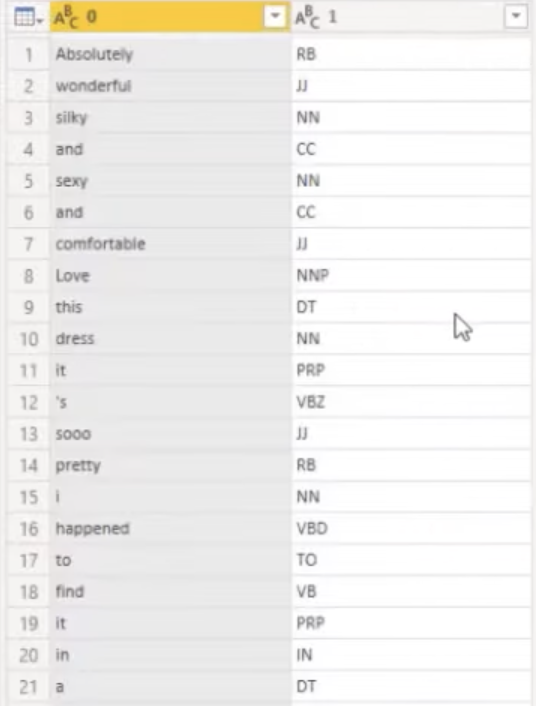
In the old version of this same text analysis, I called the first column as Word and the second as Abbreviation.

In the Parts of Speech query, we bring in the actual words that are for these abbreviations and connect them all together.

Now, let’s Close & Apply.
The steps we did allow us to filter through the different parts of speech that we identified using a simple Python code. It gives us this visual in Power BI where we can easily filter our text based on what parts of speech category they fall into.
***** Related Links *****
Text Analysis In Python | An Introduction
Python User Defined Functions | An Overview
Python List And For Loop In Power BI
Conclusion
As a data analyst, you may come across the need to extract insights and meaning from large amounts of unstructured text data. What you learned is a useful approach to understanding text data through text analysis.
Now, you can easily break down text into smaller units such as words and sentences, and then analyze these units for patterns and relationships. You can accomplish all these goals using text analysis in Python and Power BI.
All the best,
Gaelim Holland
[youtube https://www.youtube.com/watch?v=UkW5DvK9rqM&t=1s&w=784&h=441]
Be the first to comment